[情報] Infinity Cache 立大功,RDNA 2 架構詳解




Infinity Cache 立大功,應用於 Radeon RX 6000 系列的 RDNA 2 架構詳解
https://benchlife.info/rdna-2-architecture-detailed-with-infinity-cache/
快取就是要大、大才有效!
這次 AMD 推出採用 RDNA 2 架構的 Radeon RX 6000 系列顯示卡,可說是徹底地揚眉吐氣,該公司不僅是在 x86 處理器效能徹底贏過競爭對手 Intel,Radeon RX 6000 系列相較 NVIDIA GeForce RTX 3000 系列也是相當具有競爭力,突破過去僅能在中階主流市場對打的情況。
仔細端詳 RDNA 2 和 RDNA 內部 CU(Compute Unit)差異,除了增加 DXR(DirectX
Raytracing)必須的 Ray Accelerator 光線加速器單元之外,並沒有什麼變化,小修小改傳輸路徑與快取機制、強化 power gating 省電機制、提升時脈頻率,讓 RDNA 2 的
IPC 相較 RDNA 僅有個位數的成長。那麼接下來你會問,能夠幹掉 GeForce RTX 3090
的效能是從哪裡來的?
▼ RDNA 2 三大主軸:更高的運作時脈、Infinity Cache、支援最新的 DirectX 12
Ultimate 和 DirectStorge API 功能。
https://benchlife.info/wp-content/uploads/2020/11/001-1.jpg

如同 NVIDIA Ampere 世代,加入浮點數執行功能至原本的 INT 整數執行單元,直接讓
CUDA/Stream Processor 數量暴增,RDNA 2 世代 Navi 21 晶片設計,同樣也從前一世代 Navi 10 的 40 個 CU/2560 個 Stream Processor,翻倍暴增到 80 個 CU/5120 個
Stream Processor(Radeon RX 6900 XT 採用完全體,其餘型號依序遞減數量),這也讓持續採用 TSMC 7nm 製程的情況之下,晶片面積與電晶體數量,從 251mm2/103 億個成長至 519mm2/268 億個。
▼ RDNA 2 使用 TSMC 7nm 製程,並添加 AV1 硬體解碼與 8K HEVC 編碼能力。
https://benchlife.info/wp-content/uploads/2020/11/002-1.jpg
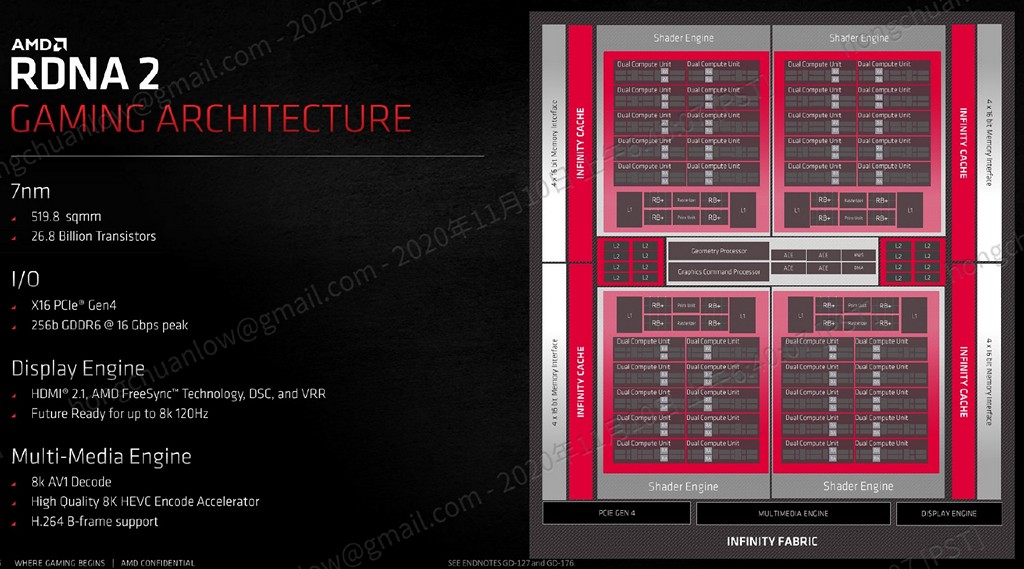
▼ 執行單元與快取的細部資訊
https://benchlife.info/wp-content/uploads/2020/11/003-1.jpg
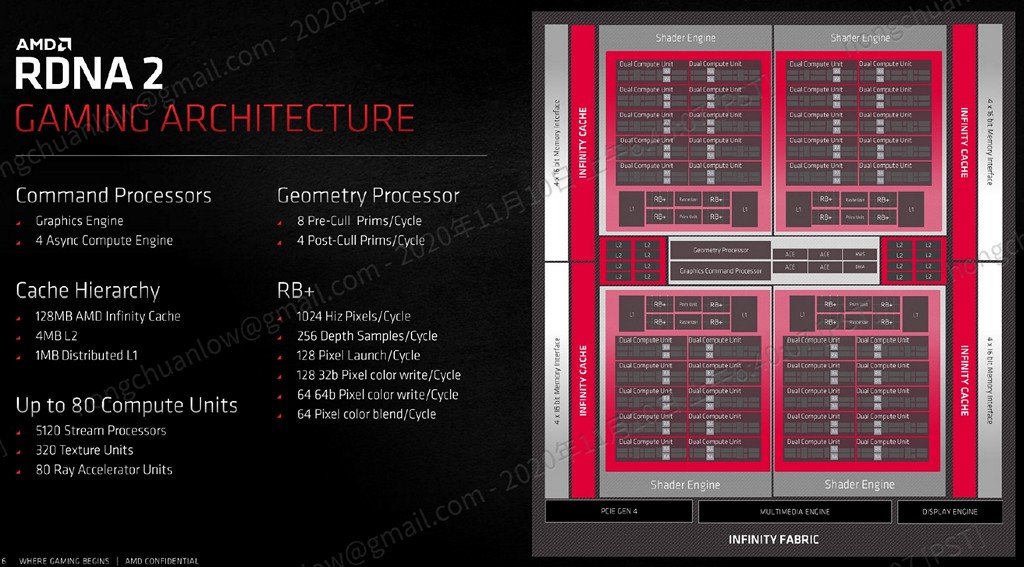
▼ AMD 替每個 CU 均添加 1 個光線加速器單元,因此 RDNA 2 的光線追蹤單元數量跟著 CU 變動,Radeon RX 6900 XT 為 80 個、Radeon RX 6800 XT 為 72 個、Radeon RX
6800 為 60 個。
https://benchlife.info/wp-content/uploads/2020/11/004-1.jpg

▼ RDNA 2 CU 面對不同類型資料的運算能力,每個時脈能夠遍歷 4 個 bonding box 或
是 1 個光線與三角形的相交檢測。
https://benchlife.info/wp-content/uploads/2020/11/004_001.jpg

▼ 每組 Shader Engine 的 RB+ 為全新設計,單一時脈週期能夠處理 8 個 32bit 色深
像素,並與光柵單元連動提供 2×1、1×2、2×2 取樣支援。
https://benchlife.info/wp-content/uploads/2020/11/004_002.jpg

128MB Infinity Cache
Stream Processor 數量成長,相對而言需要餵給執行單元更多的指令、資料,NVIDIA 採用與 Micron 合作 GDDR6X 繪圖記憶體加大頻寬。AMD 目前已確立運算、繪圖架構分立路線,運算交由 CDNA 系列搭配 HBM 類型記憶體負責,消費市場端應該不會再出現
Radeon VII 這樣的產物,在亟需頻寬的情況之下,直接在 Navi 21 晶片設計高達
128MB 的 Infinity Cache,Radeon RX 6800/6800 XT/6900 XT 各等級均可享用。
▼ Navi 21 晶片設計於 GDDR6 記憶體和 L2 快取之間,添加容量為 128MB 的
Infinity Cache。
https://benchlife.info/wp-content/uploads/2020/11/005-1.jpg

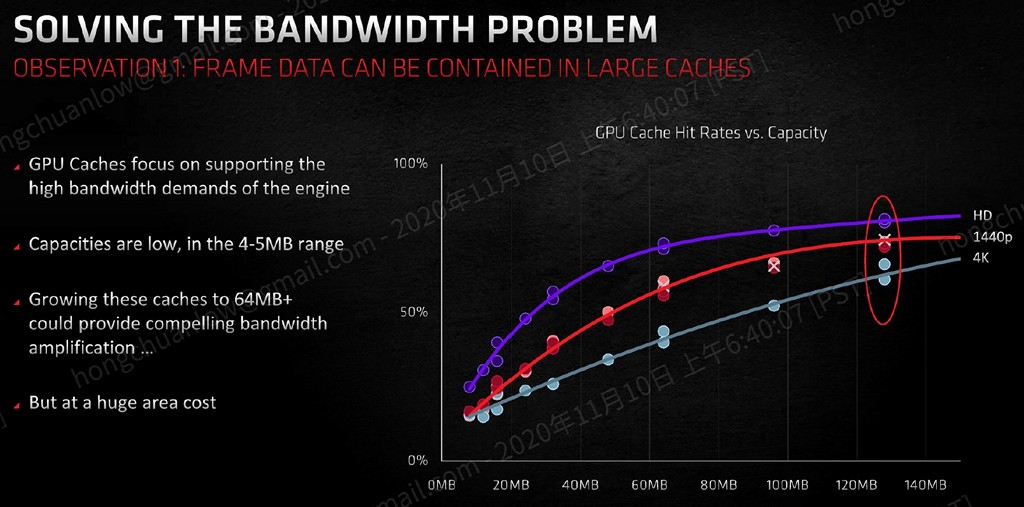
▼ 快取太小沒意義,太大又會讓晶片過胖,衡量快取命中率與容量的關係式之後,
128MB 是個比較適中的容量。
https://benchlife.info/wp-content/uploads/2020/11/012-2.jpg
Navi 21 仍舊採用 GDDR6 記憶體,匯流排寬度 256bit,搭配 16Gbps 速度版本時,可以提供 512GB/s 頻寬,Radeon RX 6800/6800 XT/6900 XT 全線均提供 16GB 記憶體容量。128MB 的 Infinity Cache 在晶片內部的匯流排寬度為 64byte x 16 通道,在最高自動加速頻率達 1.94GHz 的狀況下,能夠提供將近 2000GB/s 頻寬(基礎頻率則可提供
1664GB/s),相當驚人!
▼ Infinity Cache 採用動態時脈設定,最高可達 1.94GHz,提供將近 2000GB/s 頻寬。https://benchlife.info/wp-content/uploads/2020/11/006-1.jpg
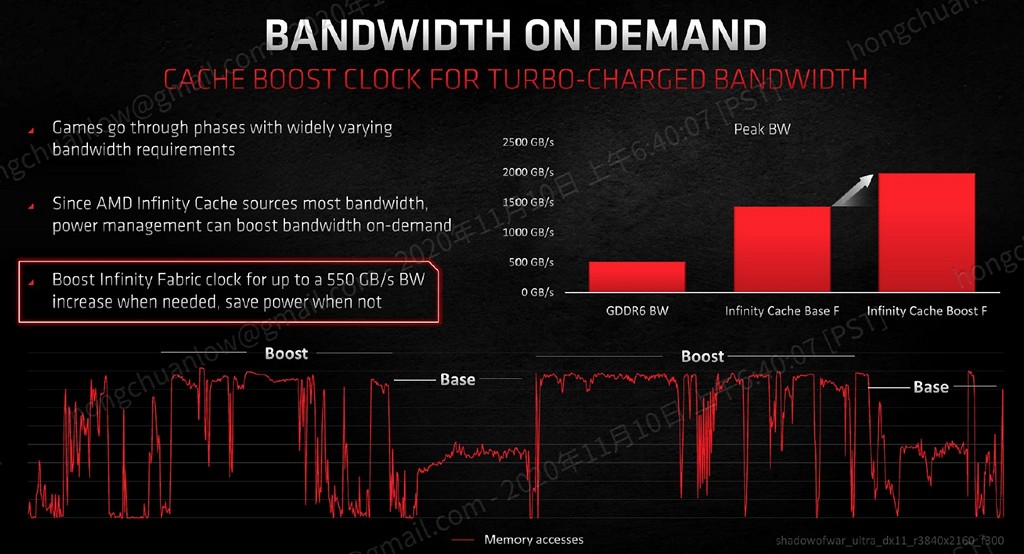
由於這個 128MB Infinity Cache 的出現,才能夠餵飽飢腸轆轆的 5120 個 Stream
Processor,也一舉讓 RDNA 2 擁有相當不錯的能源效率比值。除了傳統上的光柵化成像之外,128MB 容量也能夠擺放光線追蹤所必需的 BVH 樹狀資料結構,有助於加速光線與三角形的相交檢測,這個極度消耗晶片面積的 Infinity Cache 也算是值得了。
▼ 於圖片最左方能夠觀察到,若是沒有添加 Infinity Cache,其實 RDNA 2 相較於
RDNA 的 IPC 漲幅並不明顯。
https://benchlife.info/wp-content/uploads/2020/11/007-1.jpg
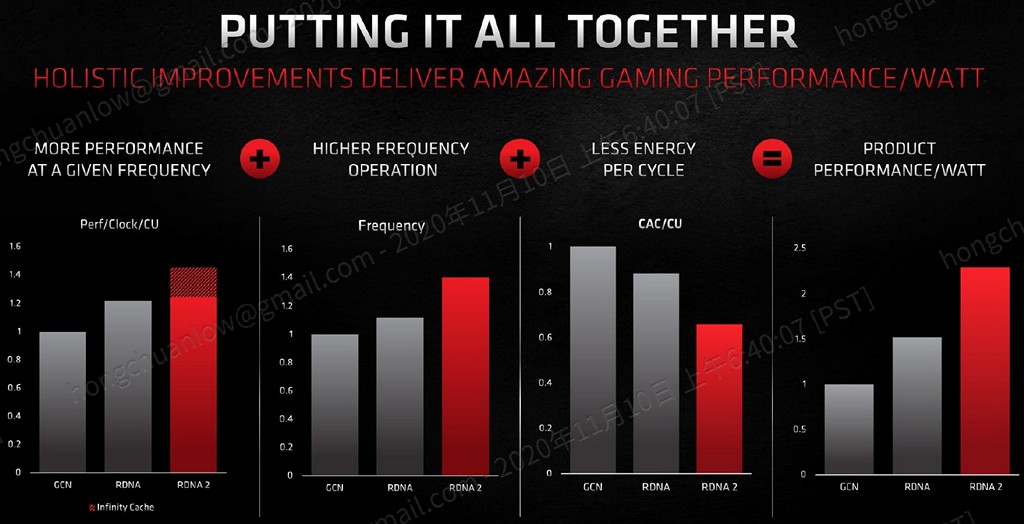
▼ Infinity Fabric 不僅提供驚人的頻寬,相對而言更能提升能源效率比值、降低存取
延遲。
https://benchlife.info/wp-content/uploads/2020/11/007-1.jpg
RDNA 2 架構也終於加入包含光線追蹤、VRS 可變速率著色(Tier 2)、Mesh Shader 網格著色器、Sampler Feedback 取樣回饋等 DirectX 12 Ultimate 功能。其實 AMD 這部分走得相當緩慢,甚至比 Intel 還要慢,Intel 早已在代號 Ice Lake 處理器的 Gen
11 繪圖核心支援 VRS,AMD 直到 RDNA 2 才算是全面導入。
▼ RDNA 2 已全面支援 DirectX 12 Ultimate。
https://benchlife.info/wp-content/uploads/2020/11/009-1.jpg

Smart Access Cahce
另一方面,AMD 終於提供 3A 平台(處理器、主機板的晶片組、顯示卡)合體加速特性,當支援的硬體相互搭配,能夠開啟所謂的 Smart Access Memory 功能,再次提升遊戲效能。縱使 AMD 於發表 Radeon RX 6000 系列顯示卡當下並未提供詳細技術資訊,之後輾轉得知其實就是 Resizable BAR 功能。
PCI 規範當中,需要每個設備自行準備 256Byte 的 Configuration Register Space,前 64Byte 儲存這個設備的 Device ID、Vender ID 等基礎資訊,後 192Byte 則是描述這個裝置究竟有什麼功能,到了 PCIe 時代,這個 256Byte 空間擴展至 4KB。處理器無法直接存取這些額外的 4KB-256Byte 空間,而是透過記憶體位址映射的方式,從高位址往下映射空間,處理器僅需讀寫這些映射空間,實際 PCIe 設備空間操作則由 PCIe Root
Complex 負責。
BAR 為 Base Address Register 的縮寫,也就是 PCIe 設備空間映射到系統記憶體的基底位址,一般來說為保持與 32 位元作業系統的相容性,BAR 通常為 256MB(1 個 PCIe系統最多擁有 256 條 Bus、每條 Bus 最多擁有 32 個設備、每個設備最多擁有 8 個功能,每個功能對應 1 個 4KB 範圍,256 x 32 x 8 x 4KB=256MB)。256MB 記憶體映射通常在 64bit 作業系統當中不會有什麼問題,因為記憶體控制器根本無法完整定址 264實體記憶體;但在比較老舊的 32bit 作業系統,你可以發現並無法完整用完 232=4GB
實體記憶體,因為部分位址已拿去作為設備 I/O 或是記憶體空間映射用途。
▼ Smart Access Memory 應該就是 PCIe 規範裡的 Resizable BAR 功能,讓處理器可以同時存取顯示卡所有的記憶體,而非預設的 256MB。
https://benchlife.info/wp-content/uploads/2020/11/010-1.jpg

為保持相容性,目前在記憶體位址中切給 PCIe BAR 的空間也都保持 256MB,但其實
BAR 能夠增加它的範圍大小,也就是 AMD 所說的完全存取顯示卡所搭載的記憶體,而非僅限於 256MB。依據 AMD 內部的實際測試,若是啟用 Smart Access Memory,最高能夠在 Forza Horizon 4 遊戲獲得 11% 的效能提升。此舉也讓綠色陣營額外表示,它們的晶片其實也支援 Resizable BAR 功能,未來會透過軟體更新開放。
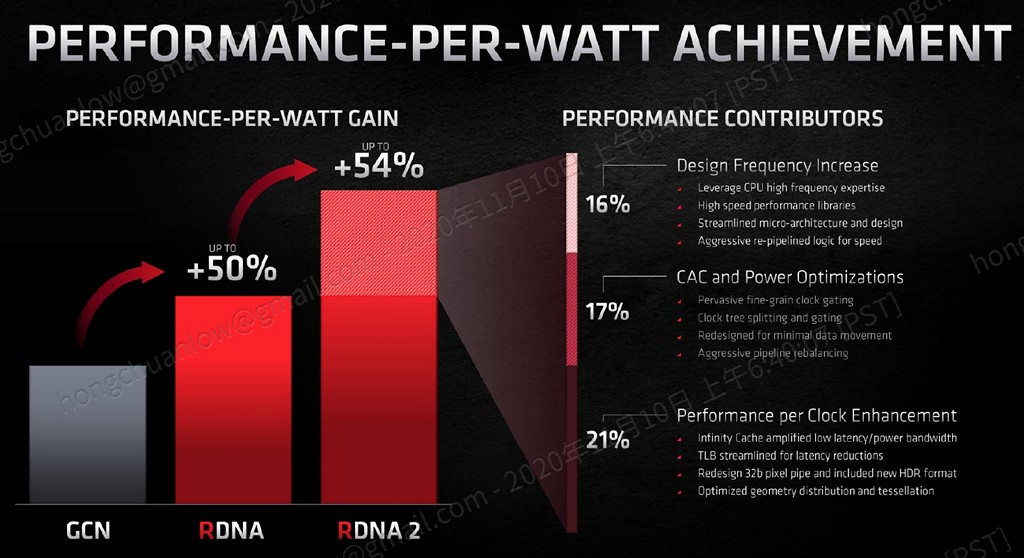
▼ RDNA 2 能源效率比值相較 RDNA 提升約 54%,其中 21% 透過 Infinity Cache 與
微調設計提供、17% 為強化省電設計、16% 為提升運作頻率。
https://benchlife.info/wp-content/uploads/2020/11/011-1.jpg
--
打氣加油文
這次基本上能摸到30系列屁股都是靠IF cache
叭叭,到處都沒貨,叭叭
學老黃搞精簡核心有搞頭嗎? 只有CUDA才辦得到?
RNDA2已經精簡過了啦
已經把偏運算的分到CDNA去了
反而是老黃現在的架構功能愈加愈多
就是這個東西是大招之一
memory based computing 要來了
就算6800屌打3090又如何?買不到啊
那個叫 In-memory computing
不過 總算是前進了一步
if cache 怎麼好像兩者之間的電容?
最初的記憶體就是電容啊
PCI設備報的BAR 就是給cpu直接存取
32bit 定址就4gb 導致256mb這個相容的數字
現在顯卡上記憶體都gb 起跳當然不夠
Server用的運算卡也早就報好報滿
A100 上80gb 至於64bit 但cpu其實沒那麼多位置線 os
也沒實作那麼大就另一個故事
就看日後驅動的優化了
一般就39bit左右了 其他留著 要不然速度有差
N家以前就有driver存取位址用太高和os 不匹配的問題
老黃:Bar我也有,但對手給你,我才給
RDNA2 架構的 APU 會有
Infinity Cache 嗎?
解決記憶體頻寬問題
BAR是在說PCI的規範,樓上哈嘍?
*樓上上
消費性有相容性迷思 死守256mb 不像server
所以再搞個resize 認真說 你買貴貴的3080 然後裝xp
win7 32bit 沒開玩笑嗎?
6700xt以下會不會用這個技術?感覺很貴的樣子
理論上難度不高 號稱driver值5000的這麼晚才想到 該
打屁股
很貴阿 下面應該砍半起跳吧
至於n家作完有沒有11% 這就不知道了
沒有這個應該效能七折起啦
PPT做到很精美 可以繼續吹一波了
1080P贏1%=幹掉3090
97
[情報] RDNA 2 乳沫RDNA 2消息: 1. RX6000系列不只超過RDNA1 50%,而是將近60%的performance/watt性能提升 2. 全系列將搭載GDDR6記憶體,AMD曾經考慮過使用HBM,但最後沒有採用 3. 高階產品將有16GB的記憶體,但先前傳出的512-bit Bus width並不正確,可能只有256-bit 4. RDNA 2架構將加入128 MB的"infinity cache"以彌補GDDR6的記憶體頻寬![[情報] RDNA 2 乳沫](https://img.youtube.com/vi/RYV4muLkbss/mqdefault.jpg "[情報] RDNA 2 乳沫")
88
[情報] 6800XT評測:特定遊戲輾壓3080但光追母湯AMD Radeon RX 6800 XT評測:特定遊戲輾壓RTX 3080,但光追還是母湯 久違的旗艦顯卡大戰 在歷經完全沒有高階款的 Radeon RX 5000 系列後,AMD 總算在 Radeon RX 6000 系列推 出真正意義上的旗艦級 GPU 甚至搭配自家平台組成大全套還有特殊加速效果![[情報] 6800XT評測:特定遊戲輾壓3080但光追母湯](https://i.imgur.com/MWRzCH6b.jpg "[情報] 6800XT評測:特定遊戲輾壓3080但光追母湯")
79
[情報] AMD 宣布 999 美金的 Radeon RX 7900 XTXAMD 宣布 999 美金的 Radeon RX 7900 XTX 與 899 美金的 RX 7900 XT , 12 月中上市 、藉 Chiplet 設計效能大幅提升且不需升級電源與機殼 by Chevelle.fu 2022.11.04 11:02AM AMD 在台灣時間 11 月 4 日凌晨 4 點宣布公布 RDNA 3 架構的 Radeon RX 7000 系列的![[情報] AMD 宣布 999 美金的 Radeon RX 7900 XTX](https://i.imgur.com/aL9KKXOb.jpg "[情報] AMD 宣布 999 美金的 Radeon RX 7900 XTX")
20
[情報] AMD RX7950 XT顯卡傳聞詳細規格 500W TBPGreymon55透露了AMD Radeon RX 7950 XT RDNA3顯示卡據稱的規格。新規格與之前聽到的 一致 但看起來AMD可能計劃在即將推出的Radeon RX 7000系列系列中導入多個Navi 31 SKU。 從AMD Navi 31 GPU開始,這款旗艦RDNA3晶片將為下一代Radeon RX 7900 XT顯示卡提供 動力![[情報] AMD RX7950 XT顯卡傳聞詳細規格 500W TBP](https://cdn.wccftech.com/wp-content/uploads/2022/04/AMD-Radeon-RX-6000-RDNA-2-Refresh-Graphics-Cards-scaled-1.jpg "[情報] AMD RX7950 XT顯卡傳聞詳細規格 500W TBP")
18
[情報] AMD GPU 導入 Chiplets 設計,RDNA 3 將有 50% 的 Pert-Per-AMD GPU 導入 Chiplets 設計,RDNA 3 將有 50% 的 Pert-Per-Watt 提升 By Chris.L on 2022-06-10 Zen 4 處理器介紹完之後,緊接著就是近期沒有太多聲音的 RDNA 3 GPU。 預期在 2022 年接替 RDNA 2 的 RDNA 3 GPU 架構,其實近期非常少聽到它的聲音,甚至可以用被 NVIDIA GeForce RTX 40 系列完全掩蓋來形容… 在 2022 年的財務分析師大會上 AMD 揭露部分關於 RDNA 3 以及 Navi 3X GPU 的資訊。![[情報] AMD GPU 導入 Chiplets 設計,RDNA 3 將有 50% 的 Pert-Per-](https://i.imgur.com/uJeAe7Ab.png "[情報] AMD GPU 導入 Chiplets 設計,RDNA 3 將有 50% 的 Pert-Per-")
17
[情報] AMD表示Radeon顯卡以每瓦效能性價比贏過NAMD 在部落格當中以「每瓦效能」 來衡量 Radeon RX 6000 顯示卡與對手 RTX 30 系列產品的比較 藉此表達繪圖技術致力推升每瓦效能的領先優勢 以因應能源效率設計的艱鉅挑戰,並持續致力提供更高水平的遊戲效能。 以 RX 6950 XT 來舉例:$949 美元、108 FPS、335W![[情報] AMD表示Radeon顯卡以每瓦效能性價比贏過N](https://i.imgur.com/jb3xWKub.png "[情報] AMD表示Radeon顯卡以每瓦效能性價比贏過N")
14
[情報] AMD APU拋棄Vega架構Infinity Cache 沒了RDNA2架構顯示卡產品,已經先後發布了Navi 21核心的RX 6900/6800系列 Navi 22核心的RX 6700 XT,接下來還有個更小的Navi 23 預計會用於RX 6600/RX 6500系列 甚至可能還有更入門的Navi 24。 AMD RDNA2架構的一大特點就是整合了全新設計的Infinity Cache10
+[情報] AMD RDNA3 Navi32 33將用於7700 7600XTNavi 31 GPU之後,用於AMD Radeon RX 7700 XT的Navi 32 GPU 和用於Radeon RX 7600 XT顯示卡的Navi 33 GPU也已經曝光。 RDNA3 系列將由單Die GPU和MCM GPU組成,可為下一代Radeon RX 7000系列顯示卡提供動 力![+[情報] AMD RDNA3 Navi32 33將用於7700 7600XT](https://i.imgur.com/hVuAdF1b.jpg "+[情報] AMD RDNA3 Navi32 33將用於7700 7600XT")
7
[情報] 更多 NV RTX 4090、AMD RX 7900 XT的消息最近 Twitter 用戶 Greymon55 透漏了更多關於下一代旗艦顯卡的一些規格 包括了 NVIDIA Ada Lovelace 架構的 RTX 4090,以及 AMD RDNA3 架構的 RX 7900 XT 訊息。 Ada Lovelace 架構的 AD102 GPU 採用台積電 5nm 製程,配有144組 SM,共18432個 CUDA 核心![[情報] 更多 NV RTX 4090、AMD RX 7900 XT的消息](https://www.coolaler.com.tw/image/news/21/11/nvidia_rtx_4080.jpg "[情報] 更多 NV RTX 4090、AMD RX 7900 XT的消息")
3
[情報] AMD Navi 24 RDNA2 GPU代號為Beige GobyAMD最小的RDNA 2 GPU Navi 24(代號為Beige Goby) 詳細訊息已在最新的驅動Linux顯示驅動更新中洩露 Locuza在Twitter上重點介紹了新GPU的細節 這使我們對AMD最小的第二代RDNA晶片的期望有了一個很好的概念。 根據Locuza的說法AMD Navi 24 RDNA 2 GPU將有單個SDMA引擎![[情報] AMD Navi 24 RDNA2 GPU代號為Beige Goby](https://cdn.wccftech.com/wp-content/uploads/2019/06/AMD-RDNA-Navi-GPU-Architecture_1.jpg "[情報] AMD Navi 24 RDNA2 GPU代號為Beige Goby")
![Re: [新聞] 英特爾今年以來股價暴跌 恐被踢出道瓊指](https://imgcdn.cna.com.tw/www/webphotos/WebCover/800/20241102/1024x768_398055288137.jpg "Re: [新聞] 英特爾今年以來股價暴跌 恐被踢出道瓊指")
![[閒聊] 12400T oc](https://valid.x86.fr/cache/screenshot/z0sr4y.png "[閒聊] 12400T oc")
![[開箱] 利民 Frost Vortex 140 SE 冰封漩渦](https://i.imgur.com/Xp8roNrb.jpeg "[開箱] 利民 Frost Vortex 140 SE 冰封漩渦")
![[心得] O11 VISION COMPACT與SL WIRELESS簡易心](https://i.imgur.com/55PKIpmb.jpeg "[心得] O11 VISION COMPACT與SL WIRELESS簡易心")
![[測試] 幾款SSD/SCM測試](https://i.imgur.com/NTXYSNTb.jpeg "[測試] 幾款SSD/SCM測試")