[情報] CyberAgnet 宣布導入 Deepseek




做馬娘的 CyGames 和做學偶 QualiArts 的母公司 CyberAgnet 宣布要導入 Deepseek
https://x.com/CyberAgent_PR/status/1883783524836413468
https://i.imgur.com/iqP5SzP.jpeg

--
嗚哇啊啊啊啊
這也能...公布啊? XDDDD
動作會不會太快了 到底私底下談多久
太快了吧== 是要拿來做啥
現在要使用 open sourced 語言模型很方便啊
板友們2分鐘內就都可以開始使用了
做賽馬預測
他自己都資料自己跑哪有問題
讓遊戲角色自由對話嗎
所以SV2要出來了沒?
用在哪呀?智能客服嗎?
好奇他們要拿來幹嘛
應該跟遊戲方面沒什麼關係吧,我記得CA廣告方面很早
就在用AI了
我感覺Meta決定開源 Llama 真的是很偉大的創舉XD
LLM 要普及到人人都能用 AI才會變得有用
母公司用也跟cy沒啥關係
哇操
會不會跟開源軟體xy一樣,被程式人員埋入惡意攻擊
這模型3070跑的起來嗎?我只有這個QQ
這個開源的東西也只是訓練好的係數
看起來就想弄日文版的 畢竟大陸弄中文搞超久了
@jojojen 14B 那個我的 RTX4070 就有點吃力了
CA很早就一直在研究ai了 他們職缺也一直有在招聘研究員
不太意外
CA看起來是要直接用他們訓練好的結果吧?
最近很認真地在考慮要不要買 5090 XDDD
這不是要使用 是發布基於deepseek額外對日文訓練的模型
GPT太貴了 市場大餅要被國家機器搶走了
Ok 放棄 那我不研究怎跑惹==
公告看起來就非營利目的 想弄日文訓練
CA這個應該是finetune完之後公開
話說這個deepseek接他常常卡住耶 太多人用了嗎
應該只是把原本的模型加上一些日文資料做fine tune 吧?
如果只是這樣很快正常呀
這玩意拿來寫劇情可能比一堆編劇好
我覺得你可以玩玩看啦 反正就下載一個大概9GB左右的東西
DS真的蠻有趣的
https://i.imgur.com/PsQHfQ8.jpg Deepseek 14B 那個模型

不認識角卷綿芽
DeepSeek撼動美股 輝達跌近17%創紀錄
用這個應該可以取代掉90%的客服
我認為客服老早就在使用了
客服的任務有很強的方向性 比較容易弄得好
問就是付費宣傳
完蛋 尊敬的佑樹
拿來做中國向的遊戲不錯 啥敏感詞都會幫你挑掉
有批人要破防了
現在正是上車nv的好時機
這倒是真的 DeepSeek 對中國政治議題超敏感
那個什麼智能客服的 很多網站都在用了吧
很誠實 會用馬上公告
他是要本地部署來用還是接api啊
客服沒啥突破性吧 很多不能講的要限制 當個人助理就算了
最近某個洗廣告遊戲一看就知道拿GBF的圖丟AI去模仿
的
R1 14B只要12GB ram 好像蠻省得
32B這大小又是公開的自己架就好啦
然後沒顯卡其實也能玩 32B跑起來會有點久
但14B用CPU也算是可以接受的範圍
開源真的太神啦
我覺得 14B 用CPU有點慢了XD
不過我現在玩 DeepSeek 還沒有感覺到太驚人的部分
回應普遍比較長是真的

Deepseek驚人的地方不就是開源嗎
14B有點慢還是能玩啊 已經比janitorai還快了XD
我覺得要看模型大小 7B 8B的表現不要說比較好 簡直是災難..
我上面沒說清楚,我的意思是我覺得她跟其他開源的同樣
比較想的模型相比我暫時沒太大感覺
它是先用內心戲去猜測用戶意圖 然後再輸出
DeepSeek 8B Llama 那個我覺得大家不會太感興趣XD
7B 8B它在猜測這一步常常就錯得離譜 然後給出很糟糕的結果
什麼模型這麼先進可以塞木馬啊==
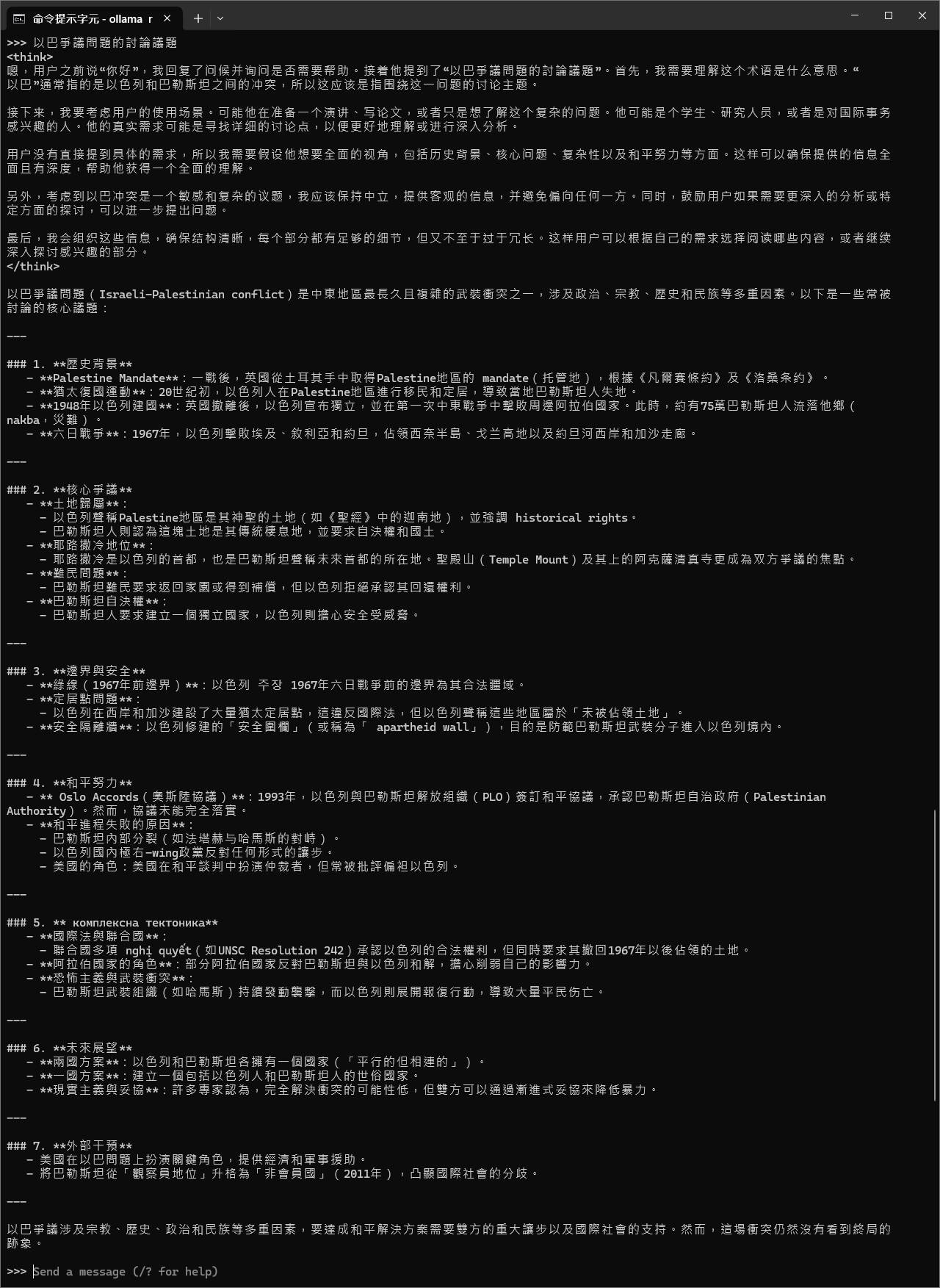
別說什麼關於中國政治議題會卡住了,我問一個「以巴爭議
問題的討論議題」這樣一個完全不含任何祖國字眼的問題,
都可以在解答內文各種輸出祖國立場…不信你各位可以嘗試
看看
嫩 老早就把馬娘系統設定拿去給DS玩惹
和openai那種中立回答不同,DS的回答非常多都是帶有立場
的
我問他台灣和中國的關係,他說台灣是中國的一部分耶哭哭
拿來寫劇情吧 難不成你期望CY會拿來平衡遊戲?
拿來賽馬
中國公司敢說台灣不是中國的嗎XD
對岸的大模型,會這樣完全是預料之中
不過他有那個種開源,那這個餅確實就有機會吃
便宜才是令人震驚的點
是CA喔 那應該研究廣告投資吧 遊戲還早
小粉紅數位板
不中立有兩種狀況,一種是在輸出強制導向某個結果(審查)
一種是訓練資料本身就偏重某個立場(偏見)
但其實其他家的AI審查跟偏見從來都不少,看議題而已
都敢開源給人驗證了 重點是他訓練成本低到不可思議
我試一下他可以回答社會主義的優缺點但是無法回答共產和
康米的一切問題
歐美AI相關全都跌到歪頭
4090應該就能跑32b的吧 還沒空試
人家明明就是說發佈了日文版 當初LLaMa也是這家發日文版
要說中國大外宣其實成本有可能低報,但能力真的這麼頂
AI門檻會越來越低,所以之前我才說不要買5070要也5070ti
沒有歪到中國那邊去 線上的就不知道了
畢竟誰知道他的system prompt設了啥呢
連三毛都不用全天候待命小粉紅
訓練方法跟配備組態都公開在pape了 成本應該可驗證吧
看來有台灣人眼紅了
日台友好!
支吹仔 啟動
別人已經在準備用中國製的AI賺錢了
有些人還只會用中國製的AI問台灣跟中國的關係和8964
是打算靠問這些問題問到開公司上櫃嗎?
都開源了 就不用分什麼誰的東西
這個成果也不是說都是純天然中國研究
你不喜歡Deepseek的話 開源模型還有很多不錯的
確實 連祖克柏都是小粉紅
但嚴格說來現在的LLM和真正的AI還差太遠,最終的追求都
是AGI
話說他把研究方法也開源了,理論上日本大企業應該也能用
同方法重新訓練一個日本版到吧,這樣就不會有尊敬的佑樹
了
兄弟 免費的
ㄟ 但重要的是現在LLM已經可以幹些不錯的事情了
全世界都是小粉紅 台灣人喔
日文資料品質跟量應該僅次於中英文,以國家層面看對日本
是大利多(如果他們的方法真的降低這麼多成本的話)
有開源資料看有沒有人能夠重現就知道成本是不是真的啊
嚴格說來我不喜歡叫這種模型開源 現在主流的「開源」模型限
制用途+無法從頭訓練 都不符合軟體界的傳統定義
DeepSeek 來說 他們沒有公開原始訓練的方式跟材料 只是給你
模型跟模型衍生物的自由散佈權 跟符合中國法規與其他合理限
制下的使用權
只有進一步訓練的程式碼是真開源
對,我記得資料集沒有公開,只是模型公開而已
所以沒有什麼重新訓練驗證成本一說
不同工具有不同用法 它對國際政局迴避就不要問這個啊 他如
果對於資料整合跟程式方面有一定水準就很好用了 而且還很
便宜
我的隱憂還是模型符合「加州」或「中國」法規差很多
V3的技術報告 不過有50多頁==
現在各方都想照著他公開的邏輯弄一套
重現得出類似的東西不就驗證低成本的可行性了嗎
大語言模型的訓練資料集到底誰會公開麻煩說一下好嗎?
然後他的licence是有哪邊不符軟體傳統定義了= =
玩了一下,DeepSeek 很多問題回答很敷衍,有些更直接裝
死
中又贏
checkpoint跟算法邏輯都公開了 是不是還要把server給你
DeepSeek沒用的唬爛話比GPT還多
把deepseek當作中國同事就好,一些敏g點別碰或故意戳,單
純談事情就很好用,畢竟chat gpt在某些地方,如歧視部分
也是很敏感,所以我覺得要用開放的心情看待
而且deepseek最強的是,它會把它怎麼想的過程跟你說,這
個有助於你思考
另外,因為這個是完全開源的,所以其他人要改成沒敏感詞
的也是可以的
然後針對類型,deepseek可以比chatgpt成本低,我有問deep
seek,我理解到的是,chatgpt比較像是萬事通,而deepseek
則是偏科的,例如語文專門或是或是理學專門,所以才這麼
省
有些人要抵制的遊戲又更多了QQ
CA我不太熟,不過他底下的CY純論企業責任是真的做的滿
足的,感覺的出他們想提升日本整體的遊戲製作水平
馬娘/RELINK的製作過程遇到的問題 經驗分享都有上傳
到公開YOTUBE,對一些獨立工作室應該很有幫助
開源的話審查也不是問題,怕審查的企業自己把程式碼下
載下來自己改自己練就沒有問題了
想了一輪我確實有錯 提到可以從頭訓練 嚴格說來不算開源定
義 算更極端的自由軟體定義了 以開源來說 我在意的是限制模
型輸出用途算不算違反開源 但我認為會爭執一段時間
畢竟這種「AI道德條款」也是一種必要之惡
例如:軟體上「禁止商用/軍用」就不算嚴格的開源
只是中國對這種術語定義很寬 能拿來用就算 也沒差
拿來分析在座各位韭菜的消費行為模式 加以農耕
要抵制了嗎
這舉動真的不行 不過老早就有很多跡象顯示這家逐漸往
西邊
deepseek肯開源表現又好,真的沒道理不跟
便宜治百病
爆
Re: [問卦] 青鳥:DeepSeek就是盜版的ChatGPT!笑死,又來一個自以為很懂的酸民 你這種鍵盤俠除了躲在螢幕後面噴口水還會幹嘛? Deepseek惹到你了是不是? 還是你根本就是那種連AI是啥都搞不清楚的雲玩家 只會跟風亂黑,可憐哪![Re: [問卦] 青鳥:DeepSeek就是盜版的ChatGPT!](https://i.imgur.com/WofCg3Ab.png "Re: [問卦] 青鳥:DeepSeek就是盜版的ChatGPT!")
爆
[問卦] 中國有Deepseek 臺灣有什麼?今天有一條震撼消息 中國自己做出了Deepseek 讓科技界跟大數據研究專家都瑟瑟發抖 現在中國遊戲也有搞頭 手機也有搞頭 還有個Deepseek爆
[問卦] 祖克柏承認DeepSeek超強了祖克柏針對DeepSeek發表感想了 祖克柏說DeepSeek很先進 美國AI很可能會落後中國 這代表中國的AI元年來臨了![[問卦] 祖克柏承認DeepSeek超強了](https://i.ytimg.com/vi/hG4tGl0s7XU/oardefault.jpg?sqp=-oaymwEkCJUDENAFSFqQAgHyq4qpAxMIARUAAAAAJQAAyEI9AICiQ3gB&rs=AOn4CLB0VEhX4AS_n6zjEwVG_IcTgg354Q "[問卦] 祖克柏承認DeepSeek超強了")
爆
[情報] AMD 興奮宣布 Instinct MI300X GPUs 支援 DeepSeek-V3標題: AMD Instinct GPUs Power DeepSeek-V3: Revolutionizing AI Development with SGLang 來源: AMD's X (Twitter) 網址:![[情報] AMD 興奮宣布 Instinct MI300X GPUs 支援 DeepSeek-V3](https://i.imgur.com/xVyT4dsb.png "[情報] AMD 興奮宣布 Instinct MI300X GPUs 支援 DeepSeek-V3")
爆
[問卦] 大量補助台灣養的出DeepSeek嗎?這幾天Deepseek引起全球熱議,沒想到對岸養出便宜又高效能的AI系統。 AI島、科技之島、晶圓之島,世界難波萬的台灣,要是靠政府補助,養的出DeepSeek嗎? --![[問卦] 大量補助台灣養的出DeepSeek嗎?](https://i.imgur.com/ilR9pDfb.jpg "[問卦] 大量補助台灣養的出DeepSeek嗎?")
38
[問卦] 財經網美說Deepseek開發成本謊報中國AI公司DeepSeek(深度求索)以低晶片數開發出與OpenAI O1相當的新模型,經過查 詢成本降低98%引外界矚目,對此財經網美胡采蘋認為,DeepSeek的母公司「幻方量化」 聲稱,他們是用A800、降速晶片開發,這根本是無從驗證的說法,且Deepseek沒有報上背 後語言模型的成本,開發成本必然是謊報的。 但deepseek成本降98%指的根本不是開發成本![[問卦] 財經網美說Deepseek開發成本謊報](https://img.ltn.com.tw/Upload/business/page/800/2025/01/27/phpUGAksb.jpg "[問卦] 財經網美說Deepseek開發成本謊報")
34
[討論] 各國際媒體紛紛報導DeepSeek內建自我審查今天有許多國際主要媒體紛紛報導DeepSeek內建自我審查。 彭博社 how-does-china-s-ai-model-compare-to-openai-meta![[討論] 各國際媒體紛紛報導DeepSeek內建自我審查](https://assets.bwbx.io/images/users/iqjWHBFdfxIU/i47c_uxu63zM/v1/1200x802.jpg "[討論] 各國際媒體紛紛報導DeepSeek內建自我審查")
22
[問卦] deepseek超低成本計算是真的嗎?deepseek賣點就是不堆算力 改進算法用少量算力做出很大的成果 不過有人說是唬爛的 財經網美說deepseek偷偷用了五萬顆H100 光這成本就幾千萬美金了![[問卦] deepseek超低成本計算是真的嗎?](https://i.imgur.com/U7JYqIkb.jpeg "[問卦] deepseek超低成本計算是真的嗎?")
17
[問卦] deepseek會像tiktok要求賣給美國嗎沒想到deepseek效能贏ChatGPT還比較便宜 那美國會像之前對待tiktok一樣嗎 就是要求中國必須把deepseek賣給美國 不然就全球封鎖deepseek讓你只能在中國裡玩 哪國違規用deepseek就制裁誰1
Re: [新聞] 成本低廉 中國AI初創DeepSeek震撼矽谷前文恕刪 : 據報導,DeepSeek僅用2048片H800顯示卡 (GPU)、耗時兩個月,就訓練出了一個6710億參 : 數的DeepSeek-V3。相較於Meta訓練參數量4050億的Llama 3,用了1萬6384片更強的H100 : 顯示卡,花了54天。DeepSeek的訓練效率提升了11倍。 這比法很不公平
![[問卦] 中國有Deepseek 臺灣有什麼?](https://i.imgur.com/7EP3EfKb.jpeg222.250.220.247 "[問卦] 中國有Deepseek 臺灣有什麼?")